Approach
1.1 Data Pre-processing & Database Setup
.1.1 Data Pre-processing
In order to make the data given to us usable for the database, we used the file preprocessing.py, which cleans the data for us, making it usable for the queries.
The .tbl files of the TPC-H dataset are converted to .csv files for easy insertion into the PostgreSQL database, this is performed by the tbl_to_csv function within preprocessing.py. The last character of each line is removed in order to parse the database correctly into .csv format. The .csv data is then inserted into the PostgreSQL database through COPY commands from a SQL script.
.1.2 Database Setup
If you already have an existing PostgreSQL database set up and want to connect it to this application, replace the parameters (host, database, user, password, port) in the get_json method inside interface.py to match the database parameters of your local database.
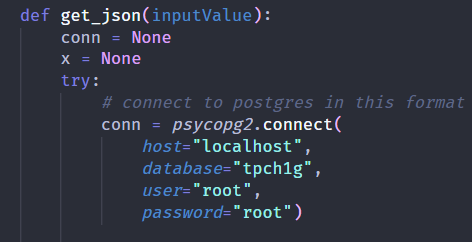
Figure 1 - get_json method for Database Connection
Alternatively, you can follow the instructions (db/README.md or 6.3 - Setting up the TPC-H database) to set up the TPC-H dataset and PostgreSQL database using Docker without any additional configurations.
.2 Obtaining Query Execution Plan (QEP)
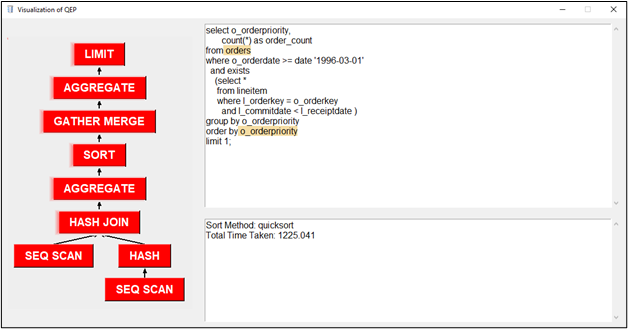
We obtain the QEP from PostgreSQL 2 commands, EXPLAIN and ANALYZE. Running “EXPLAIN ANALYZE” will return the QEP in a JSON format which we can then use for further processing.
The EXPLAIN command will show the execution plan of a statement.
The ANALYZE command will carry out the command and show actual run times and other statistics.
Design of annotation.py
2.1 Functions:
generateTree(plans, parent=None)
takes in the json file of the input query
Loops through each plan in the json file and recursively retrieves all the child nodes or a previous node
First plan is the root of the tree
That is why the function is first called without parent argument
Recursive function calls has parent in its argument as the previous node
searchTree(token, root)
Does a search through built-in pre-order iteration of the tree
Used in the buildRelation() function
searchQuery(search_value, tokens, formatted_query)
Does a full text search on query
Returns a list of index tuple of matched query tokens or None if no token matched
Used in buildRelation() function
tokenizeQuery(query_formatted)
Takes in a formatted query obtained from the the sqlparse result of the formatted JSON from the EXPLAIN ANALYZE output
Returns dictionary of tokens to be used in the buildRelation function
buildRelation(query, tree)
Matches node in the tree to tokens from the tokenized query
Returns a dictionary which is used in interface.py to highlight nodes when they are hovered
Execution Process (GUI, project.py & interface.py)
3.1 Graphical User Interface:
The graphical interface is built using Tkinter from the Python standard library. The user
interface is built to be as intuitive as possible with minimal functionalities so as to not
confuse the user.
There are two main interfaces in this project, the query input interface and the results interface, stored in the main function of project.py and Frames functions of interface.py respectively.
3.2 Query Input interface (project.py)
Upon running the program, the user will first see the Welcome Screen (Figure 2), with a space to enter a SQL query input for analyzing.
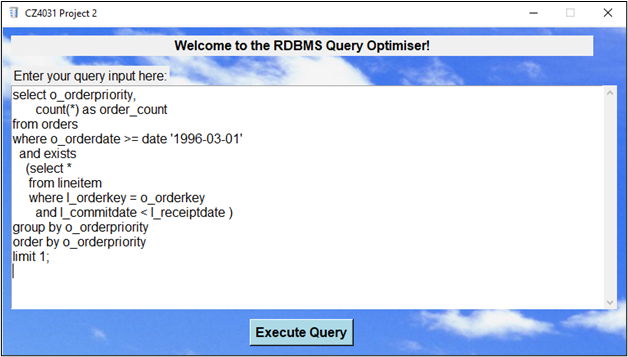
Figure 2 - “Welcome Screen”
This is achieved using various tkinter functions, to control the fonts (family, size, weight, color) and background/border colors. We also controlled the default size of the interface, directions the user can scroll, as well as placeholder input, the sizes/arrangement, etc. To improve the dynamicity of the Execute button, we added a custom-written Shadow function that highlights the button when toggled or pressed. The implementation can be seen in Figure 3.
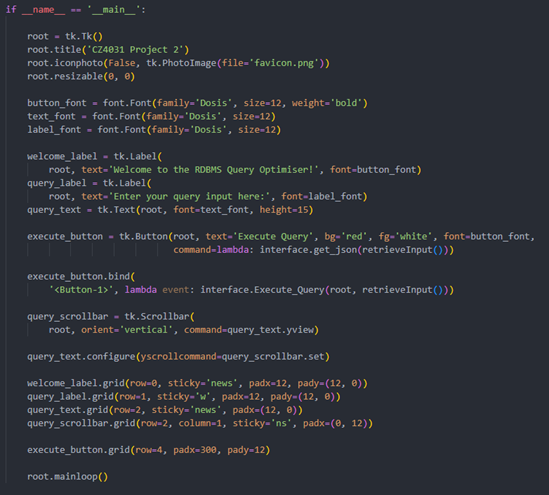
Figure 3 - Code for “Welcome Screen”